
.png)
.avif)
When people hear “DITA,” they often think of complex code and a steep learning curve. But at its core, DITA is based on one simple, powerful idea: stop duplicating content. Instead of copying a procedure or a warning message into ten different documents, you write it once and link to it everywhere it’s needed. When you need to make an update, you change it in one place, and it’s instantly corrected everywhere. This single shift from copy-pasting to linking is what makes teams so much faster. It’s the foundation of structured content, and it’s why we built Heretto, formerly EasyDITA, to make this process seamless.
Why DITA Delivers Faster, More Efficient Content
It powers faster content, at scale.
DITA is faster for a number of reasons, which we’ll discuss below. But before we get into those details, let’s explore why being faster in technical content production matters to a business.
Connecting Products and People with Great Documentation
Great documentation is more than just a set of instructions; it’s a critical bridge between your product and the people who use it. For many potential customers, your documentation is a key part of their evaluation process. They look at your help content to see if your company is serious about supporting them after the sale. A well-organized, clear, and comprehensive documentation site builds immediate trust and gives people confidence that they’re making the right choice. It shows you’re invested in their success, which can turn a curious prospect into a committed customer.
This connection deepens after the purchase. When users can find answers quickly and easily, it transforms a moment of potential frustration into an experience of empowerment. This is where the power of a solid content strategy becomes clear. By creating structured content, you can deliver the right information at the right time, turning user confusion into confidence. A positive support experience doesn’t just solve a problem; it reinforces the value of your product and can turn everyday users into your most loyal advocates and fans.
How Faster Content Reduces Support Costs
Self-service is the least expensive and most preferred way for a customer to interact with a company. Not all interactions can be self-service, but for the ones that can, it’s the best. When it comes to onboarding, troubleshooting, and product support, the speed limiter is generally content. If customers can’t quickly find answers or the information they’re looking for in your content library, they contact support; it’s that simple.
Depending on your company’s situation, solving a customer’s problem with content rather than a support ticket can be 1000s or 10,000s times less expensive. It’s massively more efficient.
The simple truth is that your support costs are a function of your human-required issues + not covered self-service issues. The lowest hanging fruit is producing the content to cover all self-service issues, and in order to do this, your team needs to be faster at content production, because covering all self-service is often a lot of content.
Reducing Support Tickets with a Self-Service Portal
A self-service portal directly reduces the number of support tickets your team has to field. When customers can find answers on their own, it improves their experience and saves the company significant resources. In fact, solving a problem with content can be thousands of times cheaper than handling a live support ticket. This efficiency is a game-changer for any business looking to scale its support operations without scaling its headcount.
Companies that adopt self-service solutions see substantial operational improvements. It’s common for organizations to experience up to a 40% drop in customer support questions after launching a portal. This frees up support agents to focus on more complex issues that require a human touch. At the same time, content teams become more agile, with the ability to publish documents up to 60% faster, which keeps the self-service content fresh and accurate.
Beyond the immediate cost savings, a well-organized self-service portal builds trust with potential customers. When users can easily find comprehensive answers in your documentation, it gives them confidence in both the product and the company. A great documentation site signals that you are serious about helping them succeed, turning your content into a powerful asset for customer acquisition and retention.
Turn Your Documentation into a Sales Tool
Prospects check documentation for two primary reasons: vibe and validation.
We all know what a robust, professional documentation experience looks and feels like. It’s like walking into a hotel lobby that is well staffed, clean, organized, and well maintained. This is the vibe. It translates to trust. When prospects see that an organization takes their product documentation seriously, it builds a feeling that the organization takes their success seriously.
We all know that marketing websites are there to sell stuff, they’re there for the company. Yes, they’re helpful to us, but the primary reason a company builds a website is to generate revenue, it’s for them.
Documentation sites are the opposite. They exist exclusively to help the customer. Yes, they also help the company reduce costs, but the primary reason for the content is helping customers.
This intrinsic truth is something everyone feels. When you see a company with an extremely expensive marketing site, but a minimal or forgotten documentation experience, it shows their priorities. And, of course, the inverse is also true, and perhaps more powerful. A great documentation site builds a prospect’s confidence that they have a solid and robust place to turn when they have an issue or want more from the product they purchased.
Faster matters because building this trust creating experience requires a team to produce a lot of high-quality content on a continuous basis.
How Much Faster Can Your Team Be with DITA?
Our data points to between 2 and 3 times faster. We’ve seen this trend throughout our experience with customers and also across several surveys. Here’s the data from our latest survey on this topic.
Starting with average pages created and updated per year per author, DITA in a CCMS (not necessarily Heretto) is roughly twice the volume of the other common options.
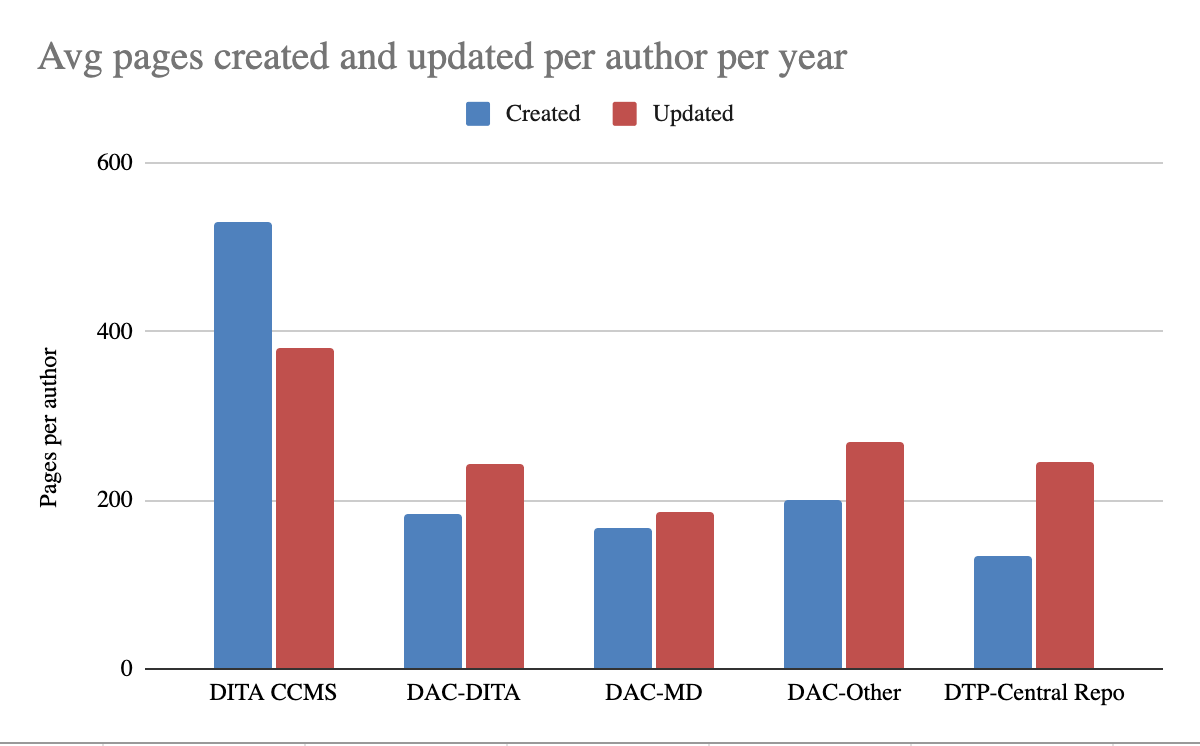
No surprise that…
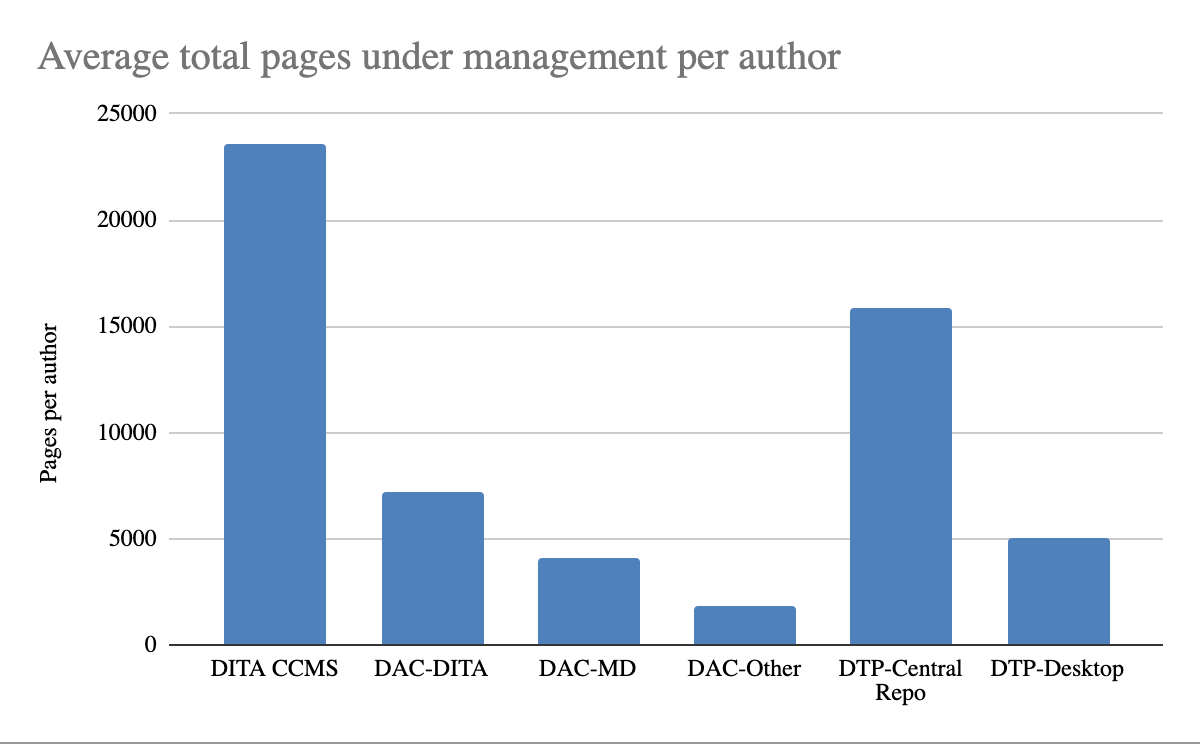
Real-World Results with Heretto
The general data on DITA's efficiency is compelling, but the results get even more specific when you use a dedicated platform. With Heretto, companies see tangible improvements across their entire content operation. For instance, teams can publish their documents up to 60% faster. This speed comes from powerful features like content reuse, which can also slash content costs by up to 90%. By creating structured content once and reusing it everywhere it’s needed, you eliminate the redundant work that slows teams down and drives up expenses. It’s about working smarter, not just harder, to get high-quality information out the door.
This efficiency has a direct impact on the customer experience and your support team's workload. After implementing Heretto's documentation portal, organizations often report up to a 40% drop in customer support questions. When customers can find answers up to three times faster, they don’t need to create a support ticket. This not only lowers operational costs but also builds customer confidence and trust in your product. You can see how this plays out for different companies in our case studies. These aren't just abstract numbers; they represent a fundamental shift in how companies support their users.
Will DITA Really Make My Team Faster?
The key question. The answer is, of course, it depends. On the graph below, the key thing to determine is where the intersection point is for your team.
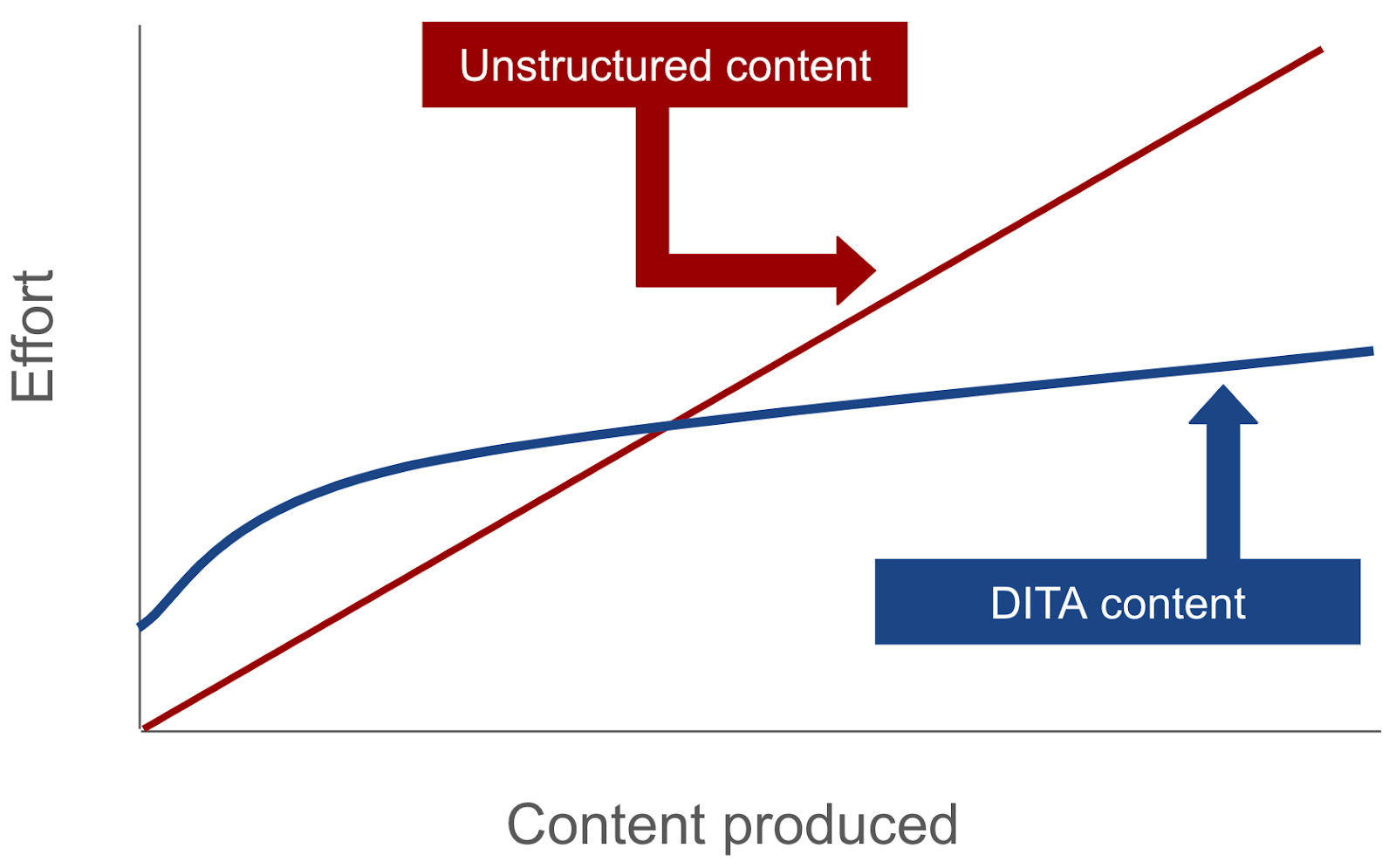
There are ways to impact the position and slope of both lines, but fundamentally, the key factors are going to be reuse, personalization, and multichannel, which are the capabilities that make DITA faster. We go into the details of how these work below, but fundamentally these are the things that impact the slope of the DITA content line.
Teams that have no potential for reuse, no need for personalization, and only publish to one place, can sometimes still see enough benefit from the efficiency of automated publishing or reduction in translation costs.
From easyDITA to Heretto: Evolving with Your Content Needs
Our journey and name evolved to better reflect the comprehensive solution we provide for modern content challenges. The shift from our previous name to Heretto represents more than a rebrand; it marks our commitment to adapting alongside the technical documentation teams we serve. As customer expectations for content have grown, so have the tools needed to meet them. We’ve expanded our platform to include new capabilities, including AI-powered tools, to help you handle the entire content lifecycle more effectively. This evolution ensures that your team has a forward-looking partner dedicated to making your content operations as efficient and impactful as possible, helping you connect your products with your audience through great documentation.
What is Heretto?
Heretto is a component content management system (CCMS) that provides an all-in-one platform for your technical content operations. Built on the power of DITA XML, it gives your team a single, centralized environment for creating, managing, and publishing structured content. Instead of juggling disconnected tools for authoring, reviews, and delivery, you can streamline your entire workflow within our system. This unified approach eliminates information silos and ensures that everyone on your team is working with the same up-to-date, approved content, which is the foundation for producing consistent and accurate documentation at scale.
By treating content as modular, reusable components, the Heretto CCMS helps you work smarter, not harder. This structure is what makes it possible to update information in one place and have it automatically reflect everywhere it’s used, saving countless hours of manual work. It also simplifies complex processes like translation management and ensures strong content governance across all your documentation. Ultimately, Heretto is designed to transform your technical content from a cost center into a valuable asset that improves customer success and builds trust in your products.
How Exactly Does DITA Make Teams Faster?
This is where we start getting into the technical details. If you want a tl;dr, it’s reuse.
Reuse comes in three different varieties:
- Source content reuse: One piece of content is used in multiple deliverables
- Personalization: One piece of content used, and altered, for different consumers
- Multichannel publishing: One piece of content used in different experiences
Source content reuse is the type of reuse most people are thinking of and referring to when they say they need reuse, but personalization and multichannel publishing are every bit as powerful and compelling for many organizations. Taken together, these three capabilities are how teams efficiently and consistently reuse content for different purposes, people, situations, and channels. And this is the single greatest capability of DITA as a methodology for content.
There are other important reasons organizations choose DITA, which we’ll go into later, but reuse is truly the central pillar of value.
The core reason we chose to build Heretto around DITA and why technical content teams choose DITA to build their content on is efficiency. DITA is about 50% more efficient than other methodologies when implemented well. Additionally, it’s the only content standard that doesn’t have scalability limits. DITA isn’t the best choice for all types of content, or even the best choice for all technical content, but it is the best choice for teams with large content sets.
Let’s look more closely at the types of reuse.
Work Smarter with Source Content Reuse
Source content reuse is often what people mean when simply referring to reuse. Reusing source content is the foundation of scalable reuse. It’s what gives teams double digit efficiency improvements through eliminating copy-paste workflows used to manage similar content across multiple documents.
The traditional way people reuse content across documents is simply to duplicate it. Often this means copying it from where it’s created and pasting it into the places it’s the same. When this is one to one between a source and end-use location, it’s often not painful enough to fix. But when copying smaller pieces between source files to account for shared content becomes required, the workflow can quickly become too expensive to do manually. There is also a governance aspect to this issue, when content is copied, its chain of custody becomes disconnected and it’s not possible to ensure the end consumer has exactly what they should.
With DITA, content is linked together rather than being copied. If I wanted to use this paragraph in another article, I would simply create a link to it and when that article was published, it would have this paragraph inserted at the position of this link. In DITA-speak, this link is called a conref, which is short for content reference. This linking to reuse content can be done at almost every level, from individual words up to entire documents.
Source reuse has downstream impacts as well. Governance, for example, is often a key driver and is enabled by a strong reuse simply because when content that is going to be used in many places is reviewed people apply more rigor and scrutiny. And while governance is its own aspect, a great deal of governance is simply ensuring that the right thing is presented to the end user and reuse is a critical capability in ensuring that result.
Collaborative Authoring in the Heretto CCMS
When multiple authors work across many documents, traditional copy-paste workflows create version control issues and inconsistencies. A Component Content Management System (CCMS) changes this dynamic entirely. In Heretto, teams aren't just editing separate, static documents; they are contributing to a centralized repository of content components. This modular approach allows authors to work on different topics simultaneously without overwriting each other's work. The focus shifts from wrangling entire documents to managing structured content, creating a more efficient and scalable system for technical documentation teams to produce and maintain information.
This collaborative environment is powered by the source reuse capabilities of DITA. When an author updates a single, reusable component—like a critical safety warning or a product setup procedure—that change automatically populates everywhere the component is used. This eliminates the tedious and error-prone task of hunting down and updating every instance of that information manually. By working from a single source of truth within the Heretto CCMS, teams can ensure the content they deliver is always consistent, accurate, and up-to-date, which directly strengthens content governance and customer trust.
Personalize Content for Every User
When most people hear the word personalization, they think of a marketing email where your name gets put in or Amazon suggesting new products based on the ones you’ve previously bought, but that’s not at all what it is in documentation.
Personalization in documentation is a type of reuse, but another way to think of it is that personalization and reuse are two sides of the same coin. Personalization is what unlocks reusing similar pieces of content rather than only being able to reuse content that is exactly the same. The most common example of this is two products that are very similar but have different names. In this case, DITA allows you to make the name a variable that changes based on the product so that you can reuse all the content around it. This is personalization, you’re personalizing the content to the product that the person owns.
Personalization is also flagging (adding metadata) to content that only applies to some audiences. A step in an install procedure may only apply to the version of a product sold in Europe. When a reader in the US sees that content, the step is removed, personalizing the content for their use case.
At a high level, personalization is just two things: switching content that is in variables and removing the content that is irrelevant for users other than the user viewing it.
Back to the statement that personalization and source reuse are two sides of the same coin. When a personalized experience is your objective, you can’t do it at any kind of scale without source reuse because without reuse the process of personalization demands that you copy content. And if the efficiency of reuse is your primary aim, you can’t accomplish it without personalization because the small differences, like names and specific call outs, in text that is otherwise identical will prevent that text from being reused. It is the synergy of these two capabilities in DITA that unlocks the value of both of them.
Reach Your Audience Everywhere with Multichannel Publishing
The only page, snippet, or answer that matters is the one a person uses. Multichannel publishing is actually the most basic form of reuse. It’s all the form of reuse that allows technical content teams to power future applications. The problem with most content is that it’s built for a single end use case. Microsoft Word documents are written to be documents. Knowledge-base articles are written in the knowledge base. Chatbot responses are built into the chatbot. And so on. With DITA, you focus on building great content in a semantically rich manner, then use pipelines to convert it into end user applications. This means you can power helpsites, in-application or in-product, AI agents, and print/PDF all from the same source, and all without any manual labor other than a publish button.
Multichannel publishing is especially important today because we’re entering into a multi-agenentic future and each agent is a channel. Organizations that want tight control over their bots and AI agents need tight control over the inputs into those bots and agents. DITA provides this by allowing teams to treat each agent as a channel and reuse content across them seamlessly and efficiently.
One-Click Publishing with Heretto Deploy
All the efficiency gained from reuse and personalization comes together at the final step: publishing. This is where your structured content becomes a tangible asset for your customers. Heretto Deploy simplifies this entire process into a single action. With one click, you can send your DITA content to all its destinations—help websites, customer portals, PDFs, and even AI chatbots. This automated approach to publishing ensures your content is consistent everywhere, building trust with your audience. More importantly, it’s incredibly fast. By removing the manual labor of formatting content for different channels, teams can publish their documentation up to 60% faster, getting critical information to users exactly when they need it.
How Extensibility Makes DITA Work for You
Rarely do teams think about extensibility when they’re first getting into structured content, but it is an important capability for future growth and applications, and it’s one of the things that truly sets DITA apart. So even though DITA’s extensibility is less talked about than reuse and harder to put hard ROI numbers to, it’s no less important for large organizations looking to standardize. In DITA terminology, the ability to extend the content model is called specialization. This is because the process of extending your DITA content model is taking one piece, typically an element, and making a new, special version of it.
The secret sauce that makes this so unique and powerful in DITA is that your new element is both the new version and the original at the same time. This means that an organization can introduce and use new rules and semantics into their content model without disrupting those who are using the current version. This is what enables large organizations to collaborate across teams.
Accelerate Workflows with AI
Beyond the structural efficiencies of DITA, modern content operations also get a major speed improvement from artificial intelligence. AI tools designed for structured content can help at both ends of the content lifecycle: creation and delivery. For writers, AI can handle repetitive tasks and offer expert guidance, freeing them up to focus on creating clear, high-quality information. For customers, AI can power search and answer engines that deliver precise, trustworthy information instantly, which is the ultimate goal of any self-service strategy. These tools don’t replace human expertise; they amplify it, making your entire content workflow faster and more effective.
Etto: Your DITA-Expert AI Assistant
Think of having a DITA expert sitting next to you, ready to help with the tedious parts of content creation. That’s the idea behind tools like Etto, the Heretto Copilot. This AI assistant is built directly into the authoring environment to help writers work more efficiently. It can handle routine tasks, suggest structural improvements, and ensure content adheres to DITA best practices. By offloading some of the mechanical aspects of structured authoring, Etto allows writers to concentrate on what they do best: crafting accurate and helpful documentation that guides customers to success.
HelpAI: Instant, Reliable Answers for Your Customers
Once your content is published, the next challenge is making sure customers can find the answers they need. This is where an AI-powered search tool like HelpAI comes in. Integrated into the Heretto Portal, HelpAI provides users with immediate, reliable answers drawn directly from your documentation. It gives each result a confidence score and shows exactly where the information came from, building customer trust. This turns your documentation from a static library into a dynamic, interactive resource that solves problems on the spot, reducing the need for support tickets.
Create a Centralized Knowledge Hub with Heretto Portal
Creating great content is only half the battle; you also need a single, reliable place to publish it. A centralized knowledge hub ensures that every customer, prospect, and internal team member gets consistent information from one source of truth. This prevents the confusion that arises when support articles, product docs, and marketing materials offer conflicting advice. By consolidating all your technical content into one portal, you create a seamless and trustworthy experience that makes it easy for users to find what they need, whenever they need it.
Integrating API Documentation
A common point of friction is the separation between product documentation and API documentation. Developers often have to switch between different sites and platforms to get a complete picture. You can eliminate this issue when you integrate interactive API documents directly into your knowledge hub. Bringing product and developer documentation together in one place provides a smooth, unified experience for everyone. This not only helps your developer audience but also reinforces the idea that all your content is part of one cohesive, well-managed ecosystem.
DITA vs. Other Structured Authoring Approaches
While DITA is a powerful standard, it’s not the only structured authoring approach available. Other options, like DocBook, have been used for technical documentation for years. However, the key difference lies in DITA’s design for topic-based authoring and content reuse. When implemented well, DITA can be about 50% more efficient than other methods for creating and managing content. This efficiency is critical for teams that need to produce a large volume of high-quality documentation to support complex products and cover all potential self-service needs.
Considering DocBook
DocBook is a semantic XML markup language that is well-suited for long, book-like documents. It’s a valid choice for certain types of content, but it wasn’t designed with the same level of granularity for reuse as DITA. DITA’s topic-based architecture makes it exceptionally powerful for technical content where procedures, concepts, and reference information need to be mixed, matched, and reused across many different deliverables. For organizations with extensive reuse requirements or a need to personalize content for different audiences and products, DITA provides a more flexible and scalable foundation for building a modern self-service experience.
Ready to Build a Faster Content Engine?
DITA a holistic choice for content teams. And while DITA isn’t the universal answer across all content, it is the best choice for teams who prioritize scalability, consistency, and quality.
Frequently Asked Questions
I've heard DITA has a steep learning curve. Is it really worth the effort for my team? The perception of DITA as complex often comes from thinking about it as code. It’s more helpful to think of it as a shift in mindset from copy-pasting content to linking it. While there is an initial adjustment, the long-term efficiency gains are significant. A good system handles the technical complexity behind the scenes, allowing your team to focus on writing. The real effort is in planning your content strategy, and the payoff is a faster, more scalable documentation process.
My content doesn't have a lot of identical paragraphs. How much reuse is needed to see benefits? The value of DITA extends beyond reusing identical blocks of text. It excels at managing content that is similar but not exactly the same. This is where personalization comes in, allowing you to swap out variables like product names or show specific steps for different user groups. The benefits begin when you can stop managing multiple near-identical documents and instead manage one core set of content that adapts for each audience or output.
What's the practical difference between source reuse and personalization? Think of source reuse as using the exact same ingredient in multiple recipes. You write a safety warning once and link to it in ten different procedures. Personalization is like slightly modifying that ingredient for each recipe. You write one installation guide, but use variables to automatically change the product name or metadata to hide steps that don't apply to a specific user's version. Both save time, but personalization allows you to reuse content that has minor but important differences.
How does a Component Content Management System (CCMS) like Heretto actually help with DITA? DITA provides the rules and structure for your content, but a CCMS provides the workshop to build and manage it. Instead of working with raw XML files, your team uses a streamlined authoring environment that handles the linking, version control, and review workflows. The CCMS also manages the publishing process, transforming your structured content into polished PDFs, websites, or other formats without manual intervention. It makes the power of DITA accessible to writers, not just developers.
We only publish to a website and PDF. Is multichannel publishing still relevant for us? Even if your needs are simple today, multichannel publishing is about preparing your content for the future. Your content is created in a neutral, structured format, separate from its presentation. This means if you later decide to add an in-app help feature, a knowledge base, or an AI-powered chatbot, you can use your existing content without starting from scratch. It ensures your content is an adaptable asset, ready for any channel your customers use next.
Key Takeaways
- Centralize content to eliminate redundant work: DITA's main advantage comes from replacing copy-paste workflows with content reuse. By creating a single source for a piece of information, you can update it once and have the changes appear everywhere, which speeds up production and ensures consistency.
- Turn documentation into a business asset: Producing high-quality documentation faster helps you build self-service resources that lower support costs. A professional documentation portal also builds confidence with prospects, making your content a tool for both customer success and sales.
- Deliver tailored content to any channel: DITA's efficiency isn't just about simple reuse; it also enables you to personalize content for different audiences and products. This structure allows you to publish from a single source to multiple channels, like help sites and AI chatbots, without manual reformatting.


